

今天终于在宝塔官方看到一篇 DeepSeek-R1安装文章,该方法更简单省事,容器里一次把ollama和open-webui安装了,再科普下Ollama是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。Open WebUI是一款高度可扩展、功能强大且用户友好的自托管Web用户界面,专为完全离线操作设计。DeepSeek-R1系列模型是基于Transformer架构的大型语言模型,支持中英文双语处理。该系列模型通过不断优化算法和增加训练数据,逐步提升了模型的性能和适用性。
如何30秒安装一个DeepSeek-R1 AI模型?今天牛角网全部实操体验成功后分享给大家一起学习。服务器上Ollama+open-webui+DeepSeek-R1系列模型全部搞定
配置不满足运行模型会导致服务器卡死或无法访问,请正确选择服务器配置后部署!
各模型建议的服务器配置:
2c4g可以运行1.5b,想要更流畅的话建议到8g内存,此模型可以不需要GPU
8c16g可以运行7b/8b,此模型建议使用GPU运行,建议最少使用8G运存的GPU
腾讯云性能基准测试如下:
【1.5B模型:内存占用2G左右】
2c4g(S5):生成过程中,CPU占用100%
2c8g(S5):生成过程中,CPU占用100%
4c16g(S2):生成过程中,CPU占用100%
16c64g(SA2):生成过程中,CPU占用30~40%
【7B模型:内存占用7.6G左右】
4c8g(SA2):生成过程中,CPU占用100%
16c64g(SA2):生成过程中,CPU占用50%
此使用帮助适用宝塔面板9.4.0以上的版本(2025年2月6日后发布的滚动修复包,请修复面板后安装DeepSeek-R1)
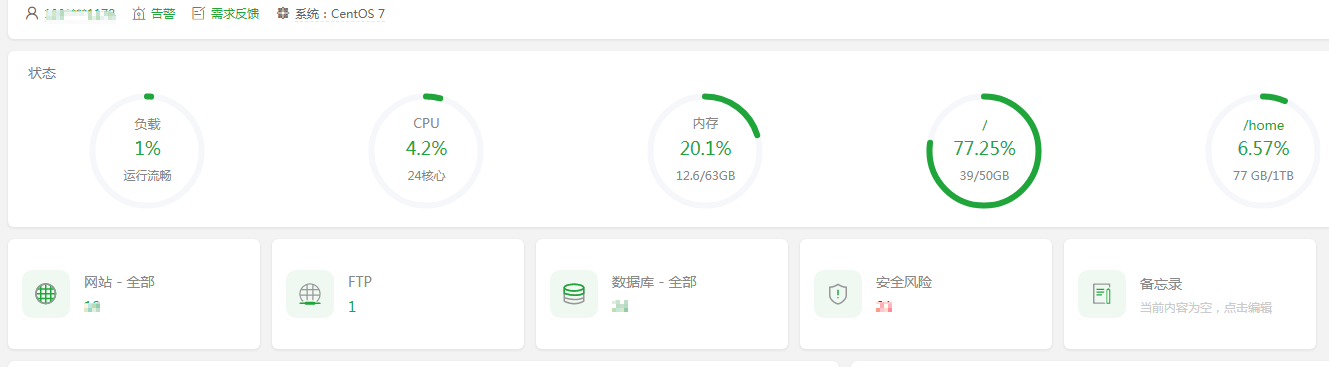
前往宝塔面板【Docker】-【应用商店】,点击DeepSeek-R1应用,点击安装即可,如果没显示DeepSeek应用,请点击右上角【更新应用列表】获取
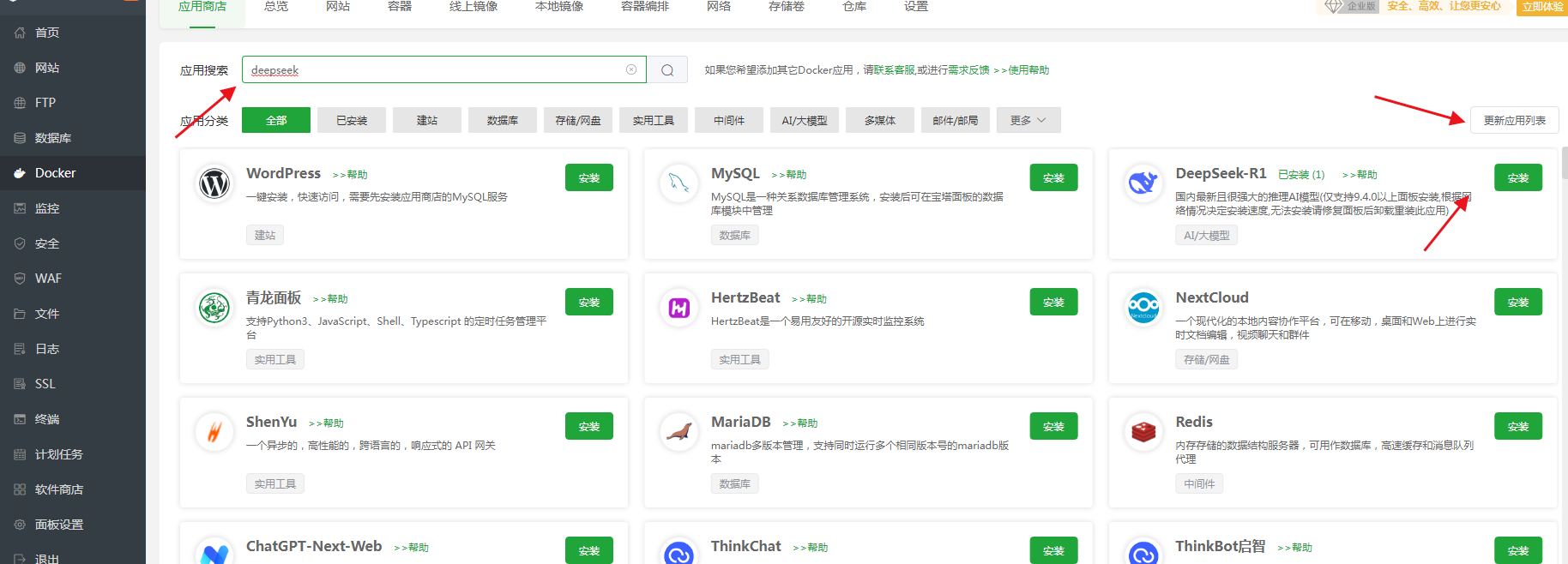
随后点击【已安装】应用的文件夹按钮,前往对应的应用目录(这里注意使用GPU时才需要这样操作),如果使用CPU默认不需要改可省略
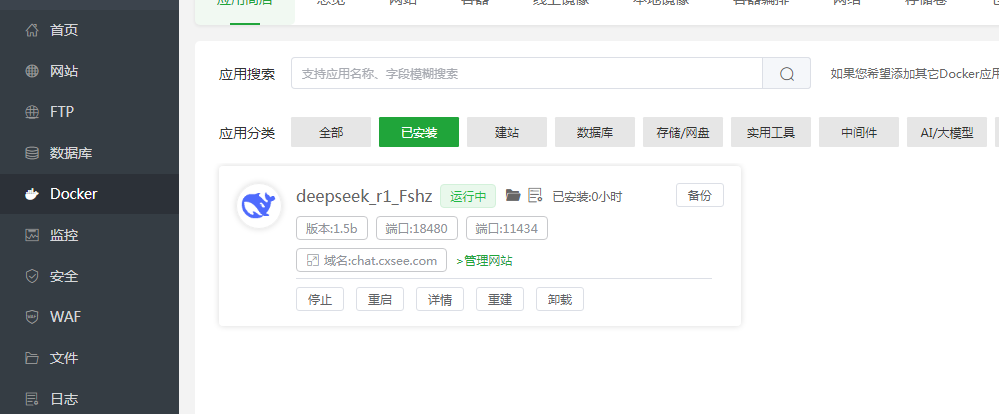
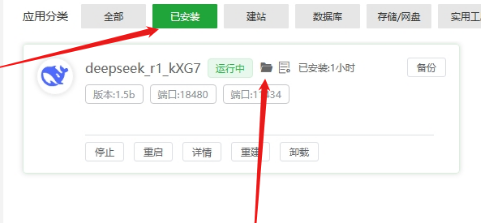
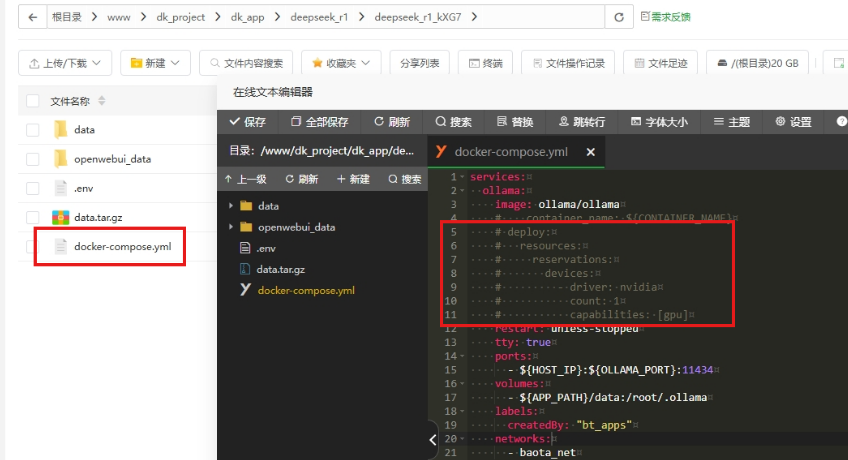
使用GPU时 编辑docker-compose.yml文件,将第5-11行的注释去掉,保存
再回到【已安装】应用界面,将此应用重启即可启用GPU支持
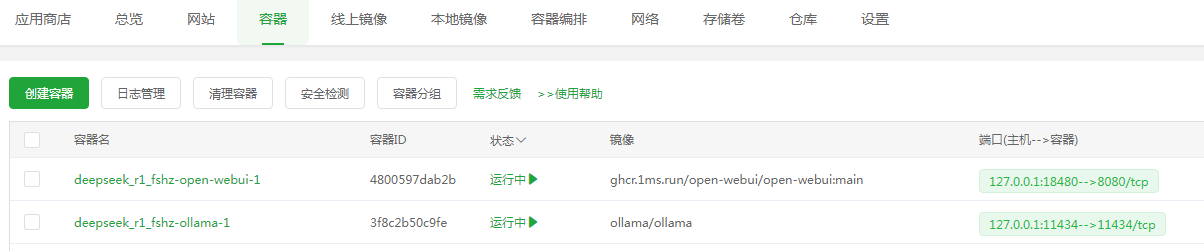
安装完成容器里面就有两个容器信息,该应用应该包含了Open WebUI一起
绑定域名访问,同时加个SSL,这样就可以通过域名打开访问Open WebUI前端了,包括反代什么的都自动帮你设置好了
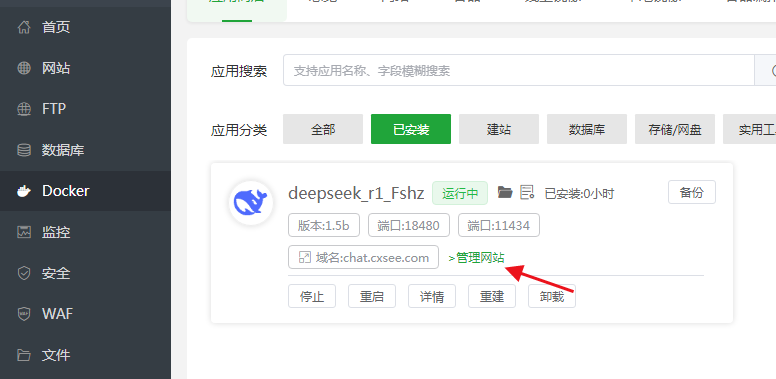
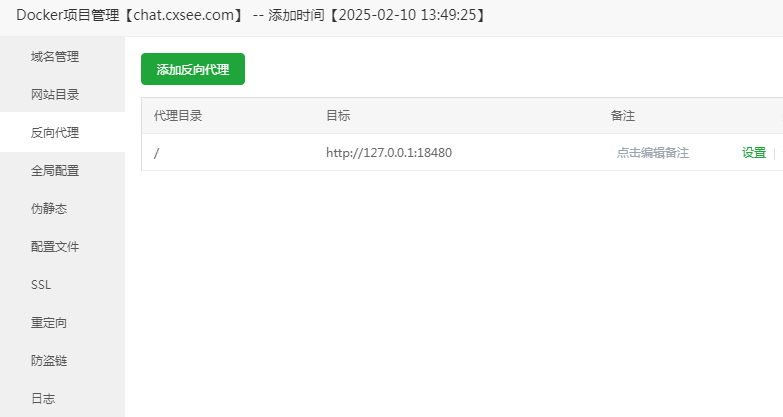
也可以手动处理反代信息,注意把安全端口放行一下
完成通过域名访问,网址打开时会提示输入管理账号密码,需要设置下,设置好就能正常进入界面
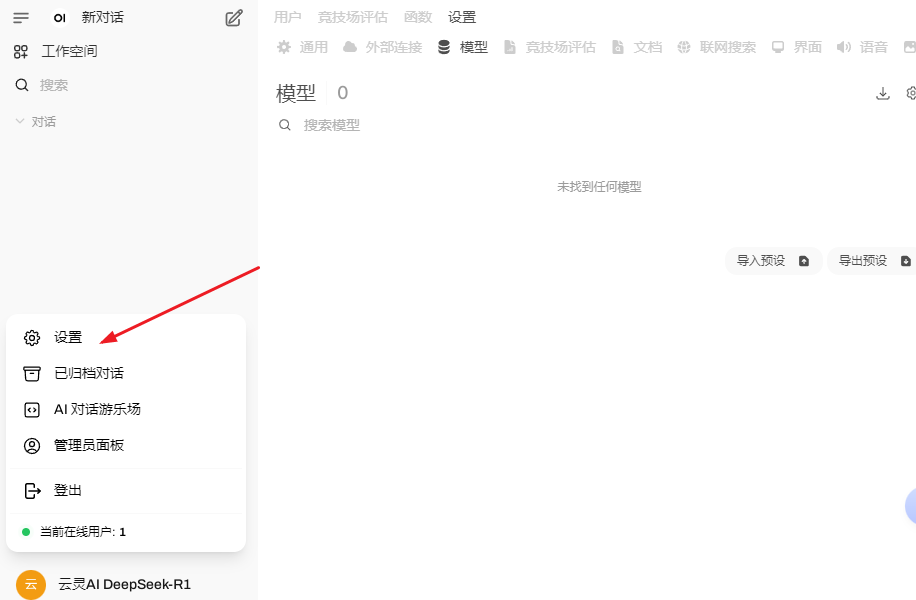
安装模型。在左下角打开设置找到模型,打开下载那个小图标
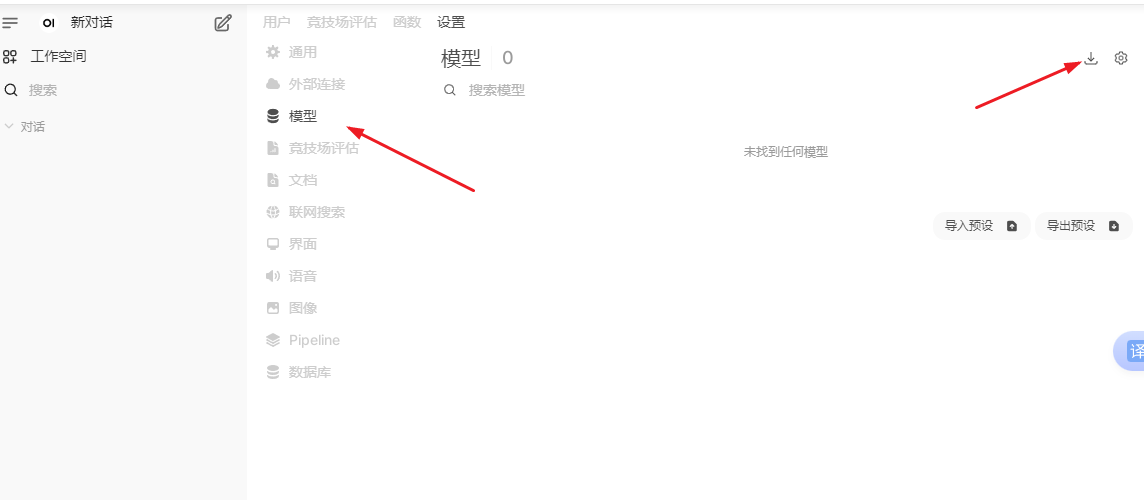
选择下载对应模型,具体需要下载什么模型可打开https://ollama.com/library/deepseek-r1:1.5b 查看
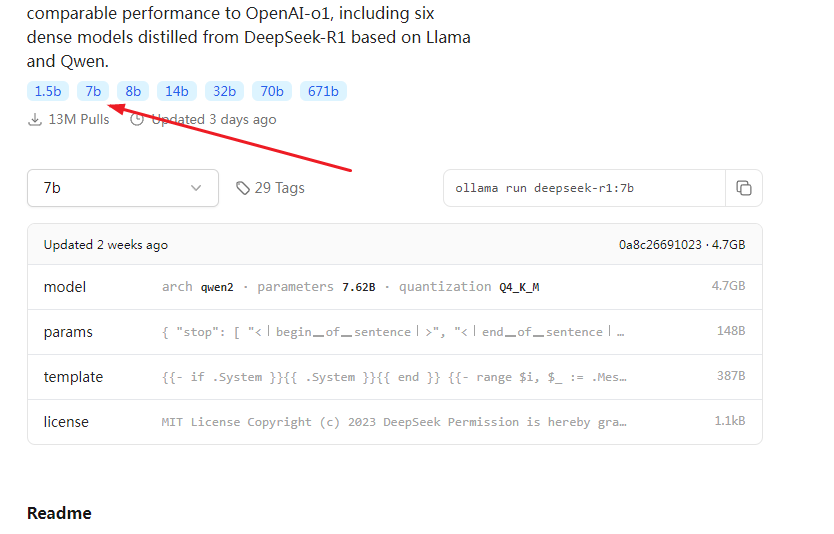
比如下载 ollama run deepseek-r1:7b 大小4.7G
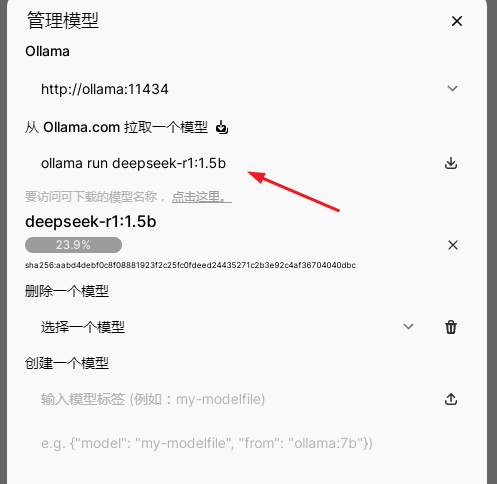
按理这步应该到此为止了,下载模型时老提示超时,这边模型也没下载成功,后面试了几次了几次下载成功,下了个最小的ollama run deepseek-r1:1.5b 大小1.5G ,模型下载非常慢
【常见问题】
1、安装成功了,但无法看到DeepSeek界面,原因是什么?
安装部署完成后,软件首次启动需要花 2 – 10 分钟时间,启动完成后可以看到 Web 界面。
2、安装成功了,但是模型输出很慢,原因是什么?
模型可能会占用大量的资源(CPU/内存/GPU),如果无法正常使用,请切换低级别的模型使用。
3、部署成功后,模型访问提示500,原因是什么?
请检查服务器内存是否足以支撑模型运行,例如:1.5b的模型需要至少1.5GB的活动内存(具体信息请查看ollama容器的日志)
4、无法访问?
注意:应用不经过系统防火墙,如果您不填写域名,勾选【允许外部访问】后是直接允许外部访问,如果您是云服务器,勾选【允许外部访问】后,请到服务器安全组放行此数据库的端口
![子比主题ACG美化插件内置功能开关100+,初一原创已开源免授权[[更新至V3.4]-观玄源码](https://plus.oocuo.com/wp-content/uploads/2024/05/20240518114412647-image-300x154.png)







暂无评论内容